
Why X's Community Notes is Struggling to Factcheck the LA Mayoral Election
The "Spencer Pratt got 0 out of 24,000 votes” rumor was obviously false. Fifty Community Notes tried to debunk it. So why did none of them appear?

A demonstrably false claim about a ballot drop in the Los Angeles mayoral race went wildly viral on X this month, contributing to the perception that the race was rigged. Dozens of people wrote Community Notes setting the record straight. Unfortunately, none of them reached consensus, because the raters couldn’t agree on verifiable facts. Since Community Notes is the centerpiece of X’s election integrity strategy, it’s worth understanding what seems to have happened here ahead of the 2026 midterms.
In the days after Los Angeles’ June 2 mayoral primary, posts began to circulate on X claiming that a late ballot update of 24,000 votes had dropped, and that Spencer Pratt – the prominent conservative challenger – had received exactly zero of them. “0/24,000,” one account wrote on a post that got 4.6 million views. “Astronomically small probability of happening. Impossible. California no longer even hides it. Doors need to be kicked in.”
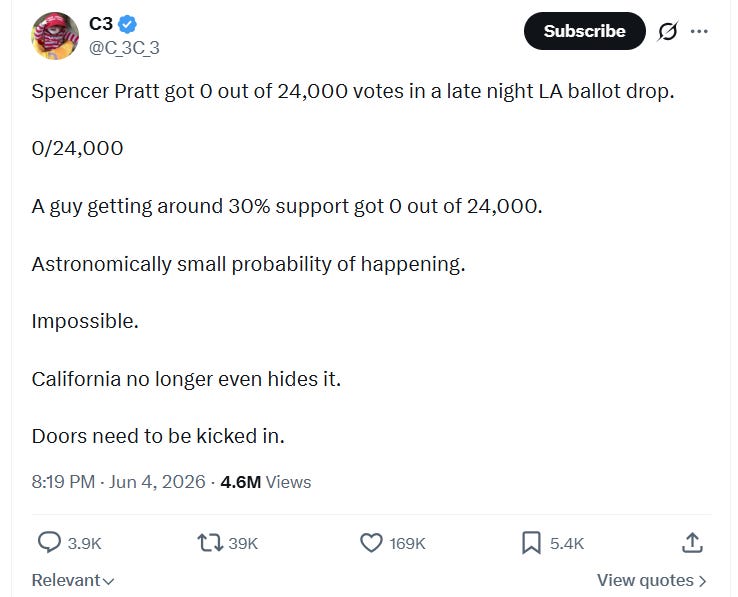
Except it wasn’t true. Over 50 notes were submitted pointing that out – by humans and AI alike. But not one managed to reach “consensus” — meaning, not one was approved by a diverse community of raters, which is what Community Notes needs in order for a note to show up. And it wasn’t a problem of too few ratings.
The bridging algorithm is celebrated for taking the pulse of diverse raters to arrive at an accurate understanding of the facts surrounding an issue, but on claims with a strong motivated partisan constituency (election fraud rumors, 2020-style lies), this situation suggests that party-line disagreement can become a veto on a basic factcheck.
And that’s alarming — both as a statement on American polarization, and on the incentives driving it.
The Case of the No Votes
Pratt’s purported zero-vote count was the result of a lag in the update of Associated Press’ automated feed during nightly ballot reporting in the LA mayoral election vote counting. During the vote drop on the night of June 3, the automated feed first pulled in totals for one group of candidates – including incumbent Karen Bass and DSA challenger Nithya Raman, which were approximately 24,000. Then, sixty seconds later, it updated with votes for the group that included Pratt.
Across those two updates, Pratt received 21,870 votes – more than Bass (12,850) or Raman (9,521). But someone screenshotted his zero-vote update during the 24,000 batch, and the snapshot of that 60-second window became a significant component of a growing “stolen election” narrative as Pratt fell from 2nd place to 3rd place in the race.
Prominent elected officials like Representative Anna Paulina Luna posted about it: “Spencer Pratt got 0 out of 24,000 ballot drops that came in … not shady at all. 🥴” (175,000 views) Elon Musk replied to and boosted accounts making the claim: “They’re not even trying hard to hide the fraud anymore.” The allegation went viral, sparking millions of views across the accusatory posts.
Leaders in California corrected the record: Governor Gavin Newsom’s press office X account called the claim “a lie.” Bill Essayli, the Trump Department of Justice’s U.S. Attorney in Los Angeles, reviewed the county’s official records and stated, “The claim is false. Each candidate received votes in every update.”
This was a checkable claim. The rumor was refutable very quickly. The data was available on the county registrar’s office, and independent sources were producing data visualizations and logs that were being widely shared; their data is all in agreement, and none shows a 0-ballot drop for Pratt. A MAGA-aligned prosecutor refuted it! Professional fact-checkers were writing debunking posts about it.
If there were ever a layup case for Community Notes – the system Elon Musk has repeatedly held up as superior to “legacy” fact-checking, and one that Meta also held up while dismantling its own third-party fact-checking program in 2025 — this should have been it.
So why did no notes show up?
What happened?
I examined a data pull from Community Notes public data (notes and status history, downloaded June 10), specifically the subset addressing the “0 of 24,000” claim. (You can search Notes data yourself using the Toronto Metropolitan University’s NoteTracker dashboard; screenshot of a general “Pratt” search below)
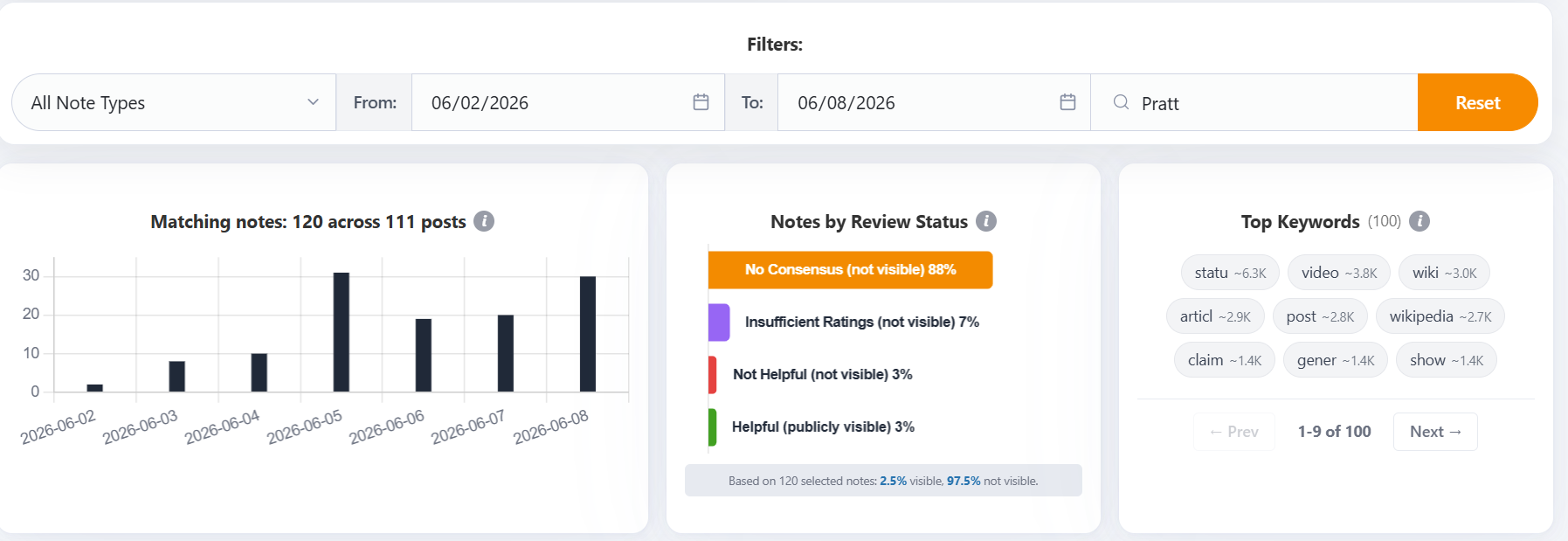
The data pull identified 60 notes across 29 posts making the claim, which had a combined ~25 million views. Fifty-one of those notes debunked the claim, citing the county’s official results page, the Decision Desk HQ feed, a project visualizing the county data. Zero of the 60 reached “Helpful” status. Across the multi-day window in which the rumor traveled from anonymous accounts advocating kicking down doors to Rasmussen Poll (”But it DID Happen“, 1MM views) to numerous large influencers, no correction appeared on any of the posts.
Fifty of the 51 accurate notes appear to be stalled. The notes, most of which were written by humans (13 of which were written entirely by AI bots), got plenty of ratings. NoteTracker’s analysis, which distinguishes under-rated notes from deadlocked ones, classifies nearly all of the Pratt-related notes in this window as “No Consensus.”
Eight of the 60 notes argued that the false claim was true, but without offering proof. One argued that the odds of Pratt’s shutout were “1 in trillions.” There was also an interesting error made by X’s own AI Collaborative Note tool, which drafts notes that highly-ranked humans in the Community Notes program can co-edit: it verified the screenshot of the purported 0/24,000 drop, not the underlying claim. On the original viral post (2.9 million views), it produced a note stating that results “show a batch where Spencer Pratt received no additional votes while others did,” citing NBC News and Wikipedia. The mechanics of the error are easy to reconstruct: the screenshots did match what news sites briefly displayed during the AP lag. Over time, the Collaborative Note updated to accurate information. (The erroneous notes also did not reach consensus)
Other incorrect notes simply appealed to Grok: “Grok says the post is correct.” (rated Not Helpful.) Grok is increasingly the main arbiter of reality on X these days. As an AI, Grok composes answers from training data plus retrieval over what has been posted and indexed. In the first hours after a breaking event it has no privileged access to ground truth. It sees what’s circulating, which is often the rumor itself. Early on it called the 0/24,000 result anomalous but allowed the data “might be incomplete”; only once corrections were indexed did it push back with accurate information.
AI does offer potential remedies to address viral rumors, and Musk has said AI will eventually write most of the context on X. LLMs can be quite good at established facts and nuanced context, but they are not oracles with instant access to the truth. An agent may soon reach out to an election official to ask for corroboration as it writes a factcheck, potentially scaling up the process, but that isn’t happening yet. For now, AI still gets things wrong, which is why humans in the loop are important. And yet, humans are in the loop with Community Notes…and perhaps can’t get out of our partisan bubbles.
The polarization problem
The fact that human reviewers could not reach consensus on the Spencer Pratt “0/24,000 votes” rumor is alarming. “No Consensus” sounds like the outcome of insufficient evidence – it’s too difficult to tell! – but the evidence in this case was not ambiguous. County records, the AP’s own explanation of its feed, a federal prosecutor who looked and found nothing. What failed to converge wasn’t the facts...it was the raters.
The Community Notes bridging algorithm requires agreement between raters who usually disagree. It works very well for scams, crypto spam, AI-generated images, out-of-context videos, and miracle cures: claims with no partisan constituency. On claims where one political faction is motivated to believe the lie, however, commitment to disbelief may have the effect of veto power over what counts as established fact. If even Trump’s own prosecutor can’t convince raters that Pratt demonstrably got votes in that drop, the question is no longer one of evidence at all. That is a crisis of trust that evidence cannot resolve, because the distrust has become untethered from facts on the ground. An audience that has heard for over a decade that every referee is corrupt views everything with suspicion; the more sources that agree, the deeper the plot must go. No correction mechanism — crowdsourced, professional, or algorithmic — can reach people who have internalized that consensus itself is a conspiracy.
There are potentially some addressable issues with the bridging algorithm: the people who rate notes on a post are downstream of who saw the post, which can sometimes lead to challenges with not enough diverse raters. But there were millions of views on those posts; many people tried to rebut the claim in the main feed.
Meanwhile, many of the rumor’s amplifiers were monetized influencer accounts. Some were influencers paid by prediction markets to post election content. Kalshi eventually asked its influencers to delete posts sowing doubt about the election, which means the gambling platforms moved faster against election misinformation on X than X’s own integrity system did. Many of the biggest spreaders of viral nonsense on X are monetized accounts. Meanwhile, note writers and raters are not compensated. This seems backwards!
If this rumor had gone viral in 2020, or 2022, the posts would likely have been labeled. The top-down factcheck-and-label process of 2020 was imperfect, but it was not a censorious tyrannical regime — it was election deniers (Jim Jordan, Eric Schmitt, Donald Trump) who led the charge to spin it as such, working to frame labeling not as a form of platform counter-speech, or more speech in general, but as “censorship.” They actively sought the “nothing is true and everything is possible” contested reality that we have arrived at, because the online attention contest goes to whomever has the biggest megaphone and the most activated audience, and because they wanted to delegitimize the referees before the next round of lies needed refereeing.
The old system at least operated on a clear theory of adjudication: a claim about a suspicious ballot dump was checked against the count and the record, and labeled if it failed. That didn’t mean the people who saw it would be persuaded; many dismissed the fact-checkers as biased. Community Notes is a genuine answer to that legitimacy problem — context from the crowd rather than from distrusted referees. But what we see in the Pratt situation is that it may be answering a narrower question: not whether a claim is true but whether people who disagree about it can agree on a note.
2026 midterms ahead...
I support Community Notes as a concept, and as a complement to fact-checking – particularly because Notes usually cite professional fact-checkers. (It’s only antagonistically framed as an either-or product by Musk and Zuckerberg for political reasons.) Notes performs well on content where partisan constituencies haven’t dug in. And when notes do appear, they measurably reduce resharing of viral false tweets. The trouble is the gap between what the system is (a useful tool in a broader information integrity strategy) and how it is being marketed: as a one-stop solution.
Elon posted recently that people who engage with posts that are subsequently Noted would see a message in their DMs. That would be worthwhile – but Notes have to appear first. A meaningful share of the extremely-online right in the US believes the LA election was stolen — their influencers are saying so, and no fact-check of even the most obviously false claims is showing up within viewing distance of the posts.
The “24,000 votes” rumor was a one-minute data lag with a public paper trail and debunks spanning PolitiFact to Trump’s own DOJ. Sixty notes, and zero corrections shown; meanwhile, millions of views on the viral posts. If consensus was impossible on this one, community contextualization will struggle to achieve what we need it to in November.
Edit: A reader points out that one note did eventually clear! You can see it here if you filter by Helpful. It’s on a satirical/sarcastic Saad post, it cites the US Attny’s tweet as well as a CNN factcheck and LA Times article. The posts it’s quote-tweeting still do not have Notes.
The notes did appear and grok did update, though. So how long was the lag before this happened? Hours?